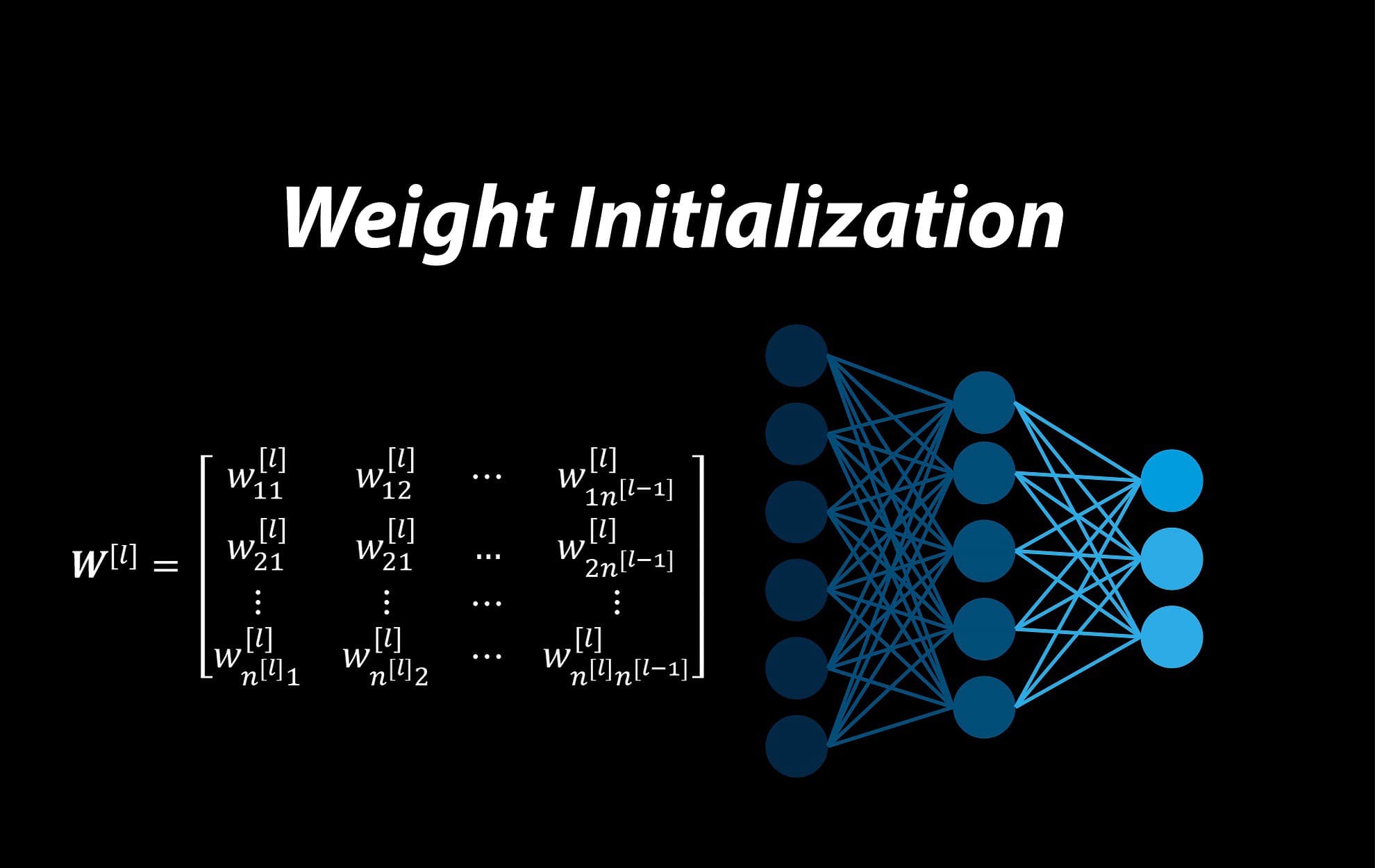
Initialization Methods in Neural Networks: Exploring Zeros, Random, and He Initialization
Introduction:
Neural networks have revolutionized the field of deep learning, enabling remarkable advancements in various domains. One crucial aspect that greatly influences the performance of a neural network is the initialization of its parameters, particularly the weights. In this article, we will explore three common initialization methods: Zeros Initialization, Random Initialization, and He Initialization. Understanding these techniques and their implications can help us design more effective neural networks.
Zeros Initialization:
Zeros Initialization, as the name suggests, involves setting the initial weights of the neural network to zero. While it may seem like a reasonable starting point, this approach is not recommended. Assigning all weights to zero means that all neurons in the network would have the same output during forward propagation, leading to symmetric behaviour and preventing the network from learning effectively. Consequently, the gradients during backpropagation would also be the same, hindering the learning process.

Random Initialization:
Random Initialization is a widely-used technique where the initial weights are set to random values. By introducing randomness, we break the symmetry and allow neurons to have different initial outputs. This enables the network to start learning diverse representations from the beginning. In practice, the random values are often drawn from a Gaussian distribution with zero mean and small variance. This ensures that the initial weights are close to zero and within a reasonable range, preventing them from becoming too large or too small.
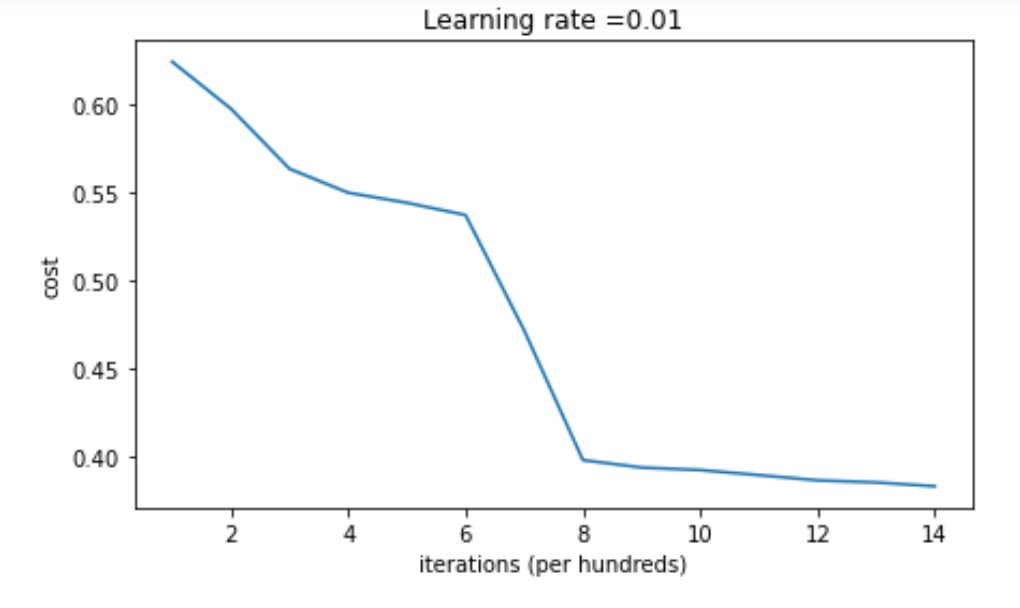
He Initialization:
He Initialization is a popular initialization method proposed by He et al. in 2015. It is specifically designed for networks that use Rectified Linear Unit (ReLU) activation functions, which are widely used due to their ability to mitigate the vanishing gradient problem. He Initialization scales the initial weights by a factor of √(2/n_l), where n_l represents the number of neurons in the previous layer. This scaling factor takes into account the variance of the ReLU activation and helps to keep it consistent across layers, facilitating stable and efficient learning.
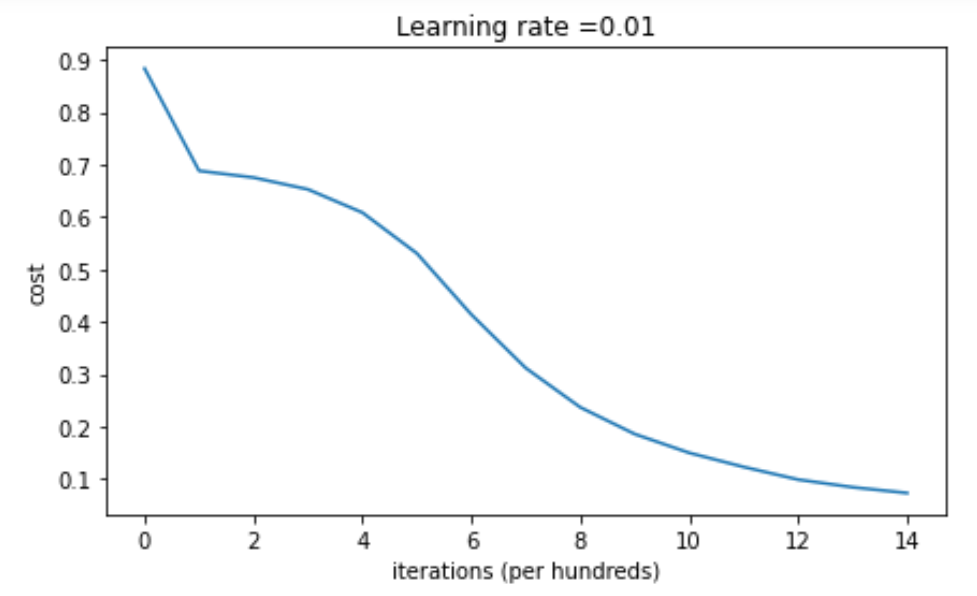
Choosing the Right Initialization Method:
To initialize parameters in a neural network using these three methods, you can specify the desired initialization technique in the input argument of your neural network framework or library. For example:
- For Zeros Initialization, set initialization = "zeros".
- For Random Initialization, set initialization = "random".
- For He Initialization, set initialization = "he".
It is worth noting that modern deep learning frameworks often have default initialization methods, such as He Initialization, to simplify the initialization process. However, it is still important to be aware of the available options and their effects on the network's performance.
Conclusion:
Proper initialization of parameters is crucial for the success of neural networks. Zeros Initialization is not recommended due to its symmetry-inducing nature, while Random Initialization and He Initialization are widely used. Random Initialization introduces diversity and breaks the symmetry, allowing for effective learning. He Initialization, tailored for ReLU-based networks, helps maintain consistent variance across layers. By understanding and utilizing these initialization methods appropriately, we can enhance the training process, enable faster convergence, and achieve better performance in our neural network models.